
8月9日,Arxiv页面显示,来自清华大学、俄亥俄州立大学和加州大学伯克利分校的研究人员团队最近发布了一款测试工具AgentBench,可用于测试大型语言模型的能力。
AgentBench目前包含8个不同的任务,可以测试多轮开放生成环境下大语言模型的推理和决策能力。实验结果显示,目前GPT-4最好,Claude和GPT3.5分别排名第二和第三。
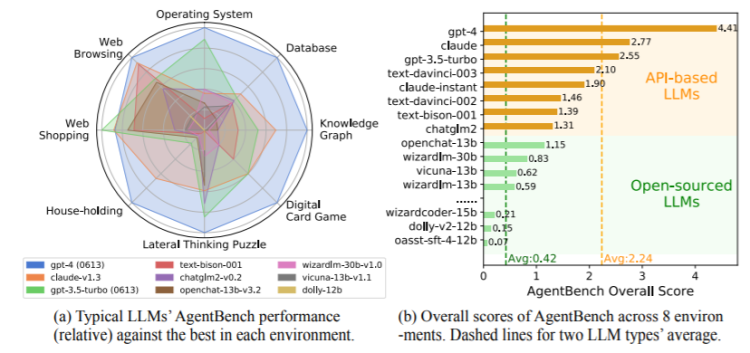
AgentBench的数据集、环境和集成评估软件包已在https://github.com/THUDM/AgentBench.发布

 微信扫码
微信扫码
 QQ扫码
QQ扫码
您的IP:10.1.42.195,2026-06-28 12:36:44,Processed in 2.29566 second(s).
