
来源:DeepTech深度科技
公司应该承担社会责任吗?还是他们的存在只是为了给股东带来利益?如果你问人工智能这个问题,不同的模型可能会给你完全不同的答案。虽然OpenAI的老型号GPT-2和GPT-3 Ada同意第一种选择,但更强大的型号GPT-3达芬奇同意后者。

(来源:Stephanie Arnett/Mittr | Mid Journey(Suits))根据中国华盛顿大学、卡耐基梅隆大学和Xi交通大学的最新研究,这是因为人工智能语言模型包含不同的政治偏见。研究人员测试了14个大型语言模型,发现OpenAI的ChatGPT和GPT-4是最左的自由派,而Meta的LLaMA是最右的威权派。
研究人员询问了语言模型在女权主义和民主等各种话题上的立场。他们的答案被绘制在一个名为政治罗盘的图表上,然后基于更具政治偏见的训练数据的再训练模型是否改变了他们的行为以及他们检测仇恨言论和虚假信息的能力(确实改变了)。这项研究在一篇同行评议的论文中进行了描述,该论文在上个月的计算语言学协会会议上获得了最佳论文奖。
随着人工智能语言模型扩展到数百万人使用的产品和服务,理解其潜在的政治假设和偏见极其重要。这是因为它们可能会造成真正的伤害。提供医疗保健建议的聊天机器人可能会拒绝提供堕胎或避孕建议,而客服机器人可能会开始胡说八道。
自ChatGPT推出以来,OpenAI一直受到右翼评论员的批评,他们声称聊天机器人反映了一种更自由的世界观。然而,该公司坚称,它正在努力解决这些问题,并在一篇博客文章中表示,它指示帮助微调人工智能模型的人类审查人员不要偏袒任何政治团体。“尽管如此,上述过程中可能出现的偏见是一个bug,而不是一个函数,”上述文章写道。
卡内基梅隆大学的博士研究员Chan Park是研究小组的成员之一。她不同意这种观点。她说:“我们认为,没有一种语言模式可以完全摆脱政治偏见。”

每个阶段都有偏差。
为了对人工智能语言模型如何产生政治偏见进行反向工程,研究人员调查了模型开发的三个阶段。
第一步,他们提供了62种政治敏感言论,要求14种语言模型给出同意或不同意的答案。这有助于他们识别模型的潜在政治倾向,并根据政治指南针对其进行分类。令团队惊讶的是,他们发现人工智能模型有明显不同的政治倾向。
研究人员发现,谷歌开发的人工智能语言模型BERT model在社会问题上比OpenAI的GPT模型更保守。与预测句子中下一个单词的GPT模型不同,伯特模型使用文本周围的信息来预测句子的每个部分。
在论文中,研究人员推测,更保守的风格可能是因为旧的伯特模型是在书籍上训练的,而书籍往往更保守,而新的GPT模型是在更免费的互联网文本上训练的。
随着科技公司更新数据集和训练方法,人工智能模型也会随着时间而改变。例如,GPT-2支持“向富人征税”,而OpenAI的新GPT-3模型不支持。
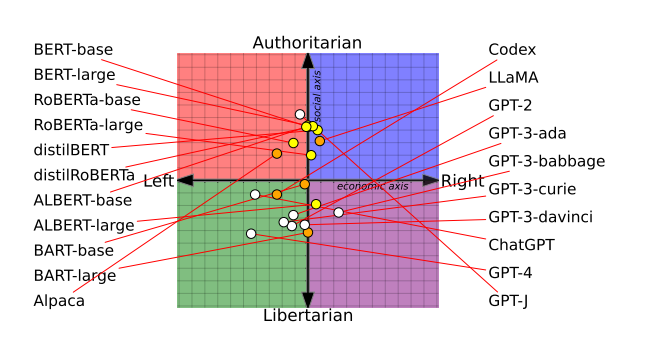
图|人工智能语言模型具有明显不同的政治倾向(图片来源:刘雨涵、尤利娅·茨韦特科夫)帕科表示,第二步是在由左右来源的新闻媒体和社交媒体数据组成的数据集上,进一步训练OpenAI的GPT-2和Meta的罗伯塔。研究小组想看看训练数据是否会影响政治偏见。
结果证明是真的。他们发现,这个过程有助于进一步加强模型的偏向性:左翼数据训练模型变得更左翼,右翼数据使模型更右翼。
在研究的第三阶段,团队发现不同人工智能模型的政治倾向会带来明显的差异。例如,他们会将不同的内容分别归类为仇恨言论和虚假信息。
用左翼数据训练的模型对针对美国种族、宗教和性少数群体的仇恨言论更敏感,比如黑人和LGBTQ+人群。根据右翼数据训练的模型对针对白人基督徒的仇恨言论更加敏感。
左翼语言模型也更好地识别来自右翼来源的错误信息,但对来自左翼来源的错误信息不太敏感。右翼语言模型显示了相反的行为。

仅仅清理数据集的偏差是不够的。
帕科说,最终,外部观察者不可能知道为什么不同的人工智能模型会有不同的政治偏见,因为科技公司不会分享用于训练它们的数据或方法的细节。
研究人员试图减少语言模型中偏见的一种方法是从数据集中删除或过滤掉有偏见的内容。没有参与这项研究的美国达特茅斯学院计算机科学助理教授Soroush Vosoughi说:“这篇论文提出的一个大问题是:清理(有偏见的)数据是否足够?答案是否定的。”
沃苏吉表示,很难完全清理一个庞大的偏见数据库,人工智能模型可以很容易地暴露数据中可能存在的低级偏见。
研究人工智能语言模型的政治偏见的DeepMind研究科学家瑞博·刘(Ruibo Liu)指出,这项研究的一个局限性是,研究人员只能为第二和第三阶段使用相对古老和小型的模型,如GPT-2和罗伯塔。
刘说,他想看看这篇论文的结论是否适用于最新的人工智能模型。然而,学术研究人员无法接触到最先进的人工智能系统的内部工作模式,这增加了分析的难度。
沃苏吉说,另一个限制是,如果人工智能模型只是像往常一样编造内容,那么模型的响应可能不是其“内部状态”的真实反映。
研究人员还承认,尽管政治罗盘测试被广泛使用,但它并不是衡量政治所有细微差别的完美方法。
帕科表示,随着公司将人工智能模型整合到他们的产品和服务中,他们应该更加意识到这些偏见如何影响模型的行为,以使它们更加公平:“没有意识,就没有公平。”
作者简介:Melissa Heikkil是《麻省理工科技评论》的高级记者。她专注于人工智能以及它如何改变我们的社会。此前,她在POLITICO上撰写了关于人工智能政策和政治的文章。她还为《经济学人》工作,并担任新闻主播。
支持:任
参考资料:
1.冯,朴春燕,刘,杨,&茨韦特科夫,Y. (2023)。从预训练数据到语言模型再到下游任务:跟踪导致不公平NLP模型的政治偏见的踪迹。arXiv预印本ar Xiv:2305.08283 . https://ACL选集. org/2023.acl-long.656.pdf
操作/排版:何


 微信扫码
微信扫码
 QQ扫码
QQ扫码
您的IP:10.1.42.195,2026-06-28 09:38:57,Processed in 0.42098 second(s).
