
随着LLM的突破性工作逐渐放缓,如何让更多的人使用LLM成为目前热门的研究方向,模型压缩可能是未来LLM的一条出路。此前,OpenAI首席科学家Ilya Sutskever表示,可以从压缩的角度来看待无监督学习。本文首次总结了关于LLM的四种模型压缩方法,并提出了今后进一步研究的可能方向,发人深省。
最近,大型语言模型(LLM)在各种任务中表现良好。然而,即使LLM具有出色的任务处理能力,它也面临着巨大的挑战,这些挑战源于其庞大的规模和计算需求。例如,GPT-175B版本有惊人的1750亿个参数,它至少需要320GB(使用1024的倍数)才能以半精度(FP16)格式存储。另外,至少需要5个A100 GPU来部署这个模型进行推理,每个GPU有80GB内存,这样才能有效保证运行。
为了解决这些问题,下一种称为模型压缩的方法可以是一种解决方案。模型压缩可以将大型的资源密集型模型转换为适合存储在受限移动设备上的精简版本。此外,它可以优化模型,以最小的延迟更快地执行,或者实现这些目标之间的平衡。
除了技术方面,LLM还引发了对环境和伦理问题的讨论。这些模型给发展中国家的工程师和研究人员带来了巨大的挑战,在这些国家,有限的资源可能会成为获得模型所需的基本硬件的阻力。LLM的大量能源消耗会加剧碳排放,人工智能研究和可持续发展也是非常重要的问题。应对这些挑战的一个可能的解决方案是使用模型压缩技术,它有可能在不显著影响性能的情况下减少碳排放。通过它,人类可以解决环境问题,增强人工智能的可及性,促进LLM部署中的包容性。
在这篇论文中,来自中国科学院信息工程研究所和全国人大人工智能研究所的研究人员高玲描述了为LLM量身定制的模型压缩技术领域的最新进展。本文对方法、指标和基准进行了详细的研究和分类。

地址:https://arxiv.org/pdf/2308.07633.pdf.
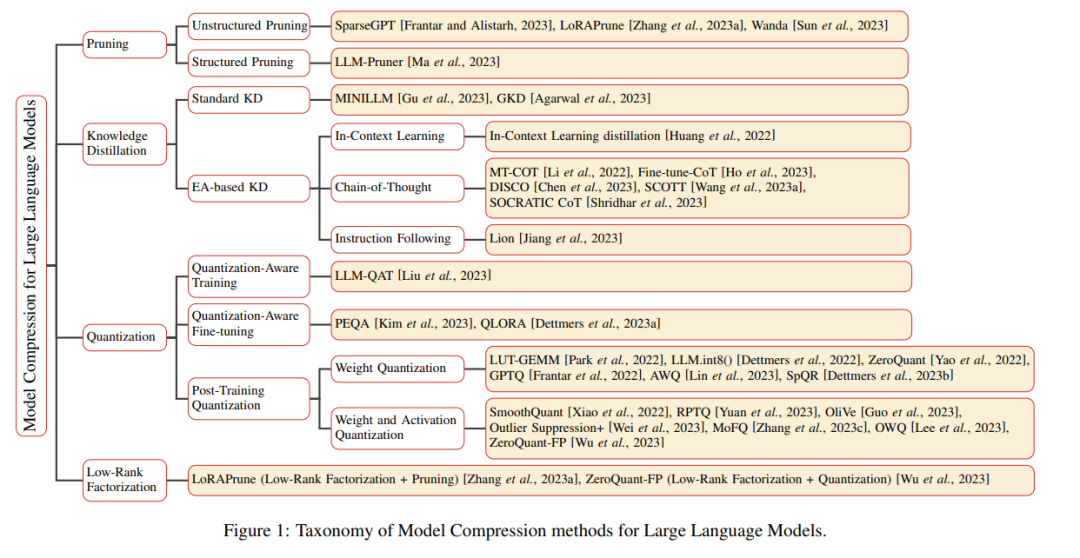
如下图1所示,本文提出的分类为理解LLM的模型压缩方法提供了一个完整的结构化框架。这种探索包括对现有成熟技术的彻底分析,包括但不限于剪枝、知识提炼、量化和低秩因子分解。此外,本文还揭示了当前面临的挑战,并展望了未来该领域潜在的研究轨迹。
研究人员还倡导社区合作,为LLM建设一个注重生态、包容和可持续发展的未来铺平了道路。值得注意的是,本文是LLM模型压缩领域的第一篇综述。
方法学
整齐
修剪是一种强大的技术,通过删除不必要的或冗余的组件来减少模型的大小或复杂性。众所周知,有很多冗余参数对模型性能影响不大,所以直接砍掉这些冗余参数后,模型性能不会受到太大影响。同时剪枝可以在模型存储、记忆效率、计算效率上更加友好。
剪枝可以分为非结构化剪枝和结构化剪枝。它们之间的主要区别在于修剪目标和产生的网络结构。结构化修剪根据特定规则切断连接或层次结构,同时保留整体网络结构。针对单个参数的非结构化剪枝会导致不规则的稀疏结构。最近的研究工作致力于将LLM与剪枝技术相结合,旨在解决与LLM相关的大规模和计算成本。
知识的升华
知识蒸馏是一种实用的机器学习技术,旨在提高模型性能和泛化能力。这项技术将知识从称为教师模型的复杂模型转移到称为学生模型的更简单模型。KD背后的核心思想是从教师模型的综合知识中转化出一个更简洁有效的代表。本文总结了以LLM为教师模型的蒸馏方法。
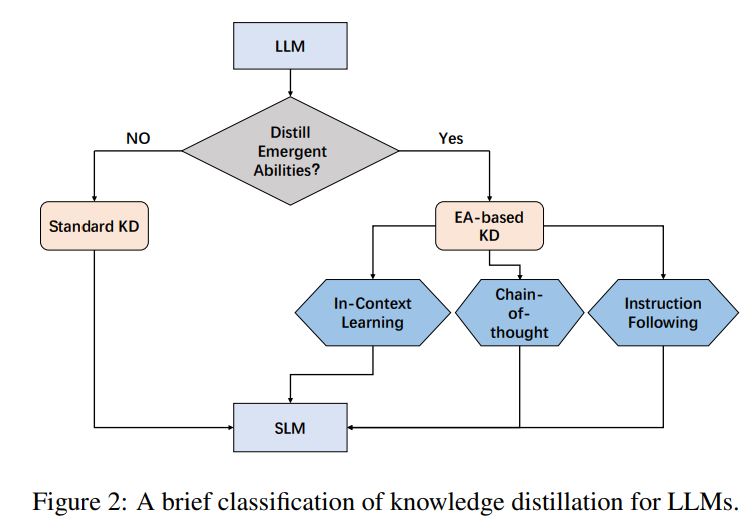
研究人员根据这些方法是否集中于提取其涌现能力(EA)到小模型(SLM)来对LLM进行分类。因此,这些方法分为两类:标准的知识发现和基于EA的知识发现。对于可视化表示任务,图2提供了LLM知识提取的简要分类。
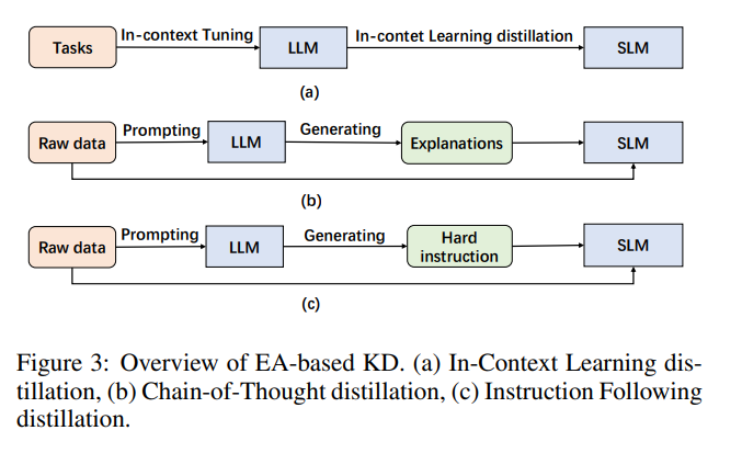
下图3显示了基于EA的蒸馏的概况。
量化
在模型压缩领域,量化已经成为一种被广泛接受的技术,以减轻深度学习模型的存储和计算开销。虽然传统上使用浮点数来表示权重,但量化会将其转换为整数或其他离散形式。这种变换大大降低了存储要求和计算复杂性。虽然会有一些固有的精度损失,但复杂的量化技术可以在最小精度下降的情况下实现大幅度的模型压缩。
量化可以分为三种主要方法:量化感知训练(QAT)、量化感知微调(QAF)和训练后量化(PTQ)。这些方法的主要区别在于何时应用量化来压缩模型。QAT在模型的训练过程中使用量化,QAF在预训练模型的微调阶段使用量化,PTQ在训练完成后对模型进行量化。
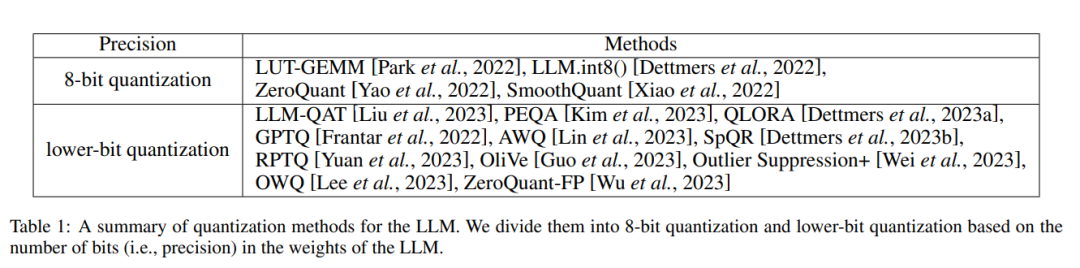
最近的研究致力于通过量化来压缩LLM,并产生了惊人的结果。这些任务主要可以分为以上三种方法:量化感知训练、量化感知微调和训练后量化。此外,下面的表1是应用于LLM的量化方法的总结。该表根据LLM权重中的位数(精度)将这些任务分为8位量化和低位量化。
低秩分解
低秩分解是一种模型压缩技术,旨在通过将给定的权重矩阵分解为两个或更多个维度显著降低的更小矩阵来逼近该矩阵。低秩分解背后的核心思想是将大权重矩阵W分解为两个矩阵U和V,使得W ≈ UV,其中U为m×k矩阵,V为k×n矩阵,K远小于M和N..u和v的乘积与原权重矩阵相似,参数个数和计算开销大大减少。
在LLM研究领域,低秩分解被广泛用于有效微调LLM,如LORA及其变体。本文重点研究了这些使用低秩分解压缩LLM的工作。在LLM模型压缩领域,研究人员经常将各种技术与低秩分解相结合,包括剪枝和量化,如LoRAPrune和ZeroQuantFP,以在保持性能的同时实现更有效的压缩。
随着该领域研究的不断深入,应用低秩分解压缩LLM可能会有进一步的发展,但要充分发挥LLM的潜力还需要探索和实验。
度量和基准
宽宏大量;容忍
LLM的推理效率可以通过多种指标来衡量。这些指标考虑了性能的不同方面,通常与LLM的准确性和零样本学习能力的综合评估一起呈现。
这些指标包括以下内容:
参数标度
模型比例尺
压缩比
推理时间
浮点运算(触发器)
基准
基准旨在衡量压缩LLM与未压缩LLM相比的有效性、效率和准确性。这些基准通常由不同的任务和数据集组成,涵盖了一系列自然语言处理的挑战。常见的基准包括但不限于浩克和ELUE。
最后,研究者认为未来应在以下几个方面进一步探索,包括
专业基准测试
绩效等级的权衡
动态LLM压缩
可解释性
更多细节请参考原论文。
剧终
授权请联系本微信官方账号。
投稿或寻求报道:content@jiqizhixin.com。

 微信扫码
微信扫码
 QQ扫码
QQ扫码
您的IP:10.1.42.195,2026-06-27 15:43:22,Processed in 0.06776 second(s).
