
大模型的上下文长度已经被卷起。
依赖注意机制的大规模语言模型(LLM)在训练时通常使用固定的上下文长度,模型能够处理的输入序列长度有上限。因此,许多研究探索了语境“长度外推”方法。
语境长度的外推是指使用用较短语境长度训练的LLM来评估较长的语言语境长度,而无需对较长的语境进行进一步训练。其中,大部分研究集中在修改注意机制中的位置编码系统。
算盘小组的研究团队。AI广泛研究了现有的基于LLaMA或LLaMA 2模型的上下文长度外推方法,并提出了一种新的截断策略。

地址:https://arxiv.org/abs/2308.10882.
项目地址:https://github.com/abacusai/long-context.
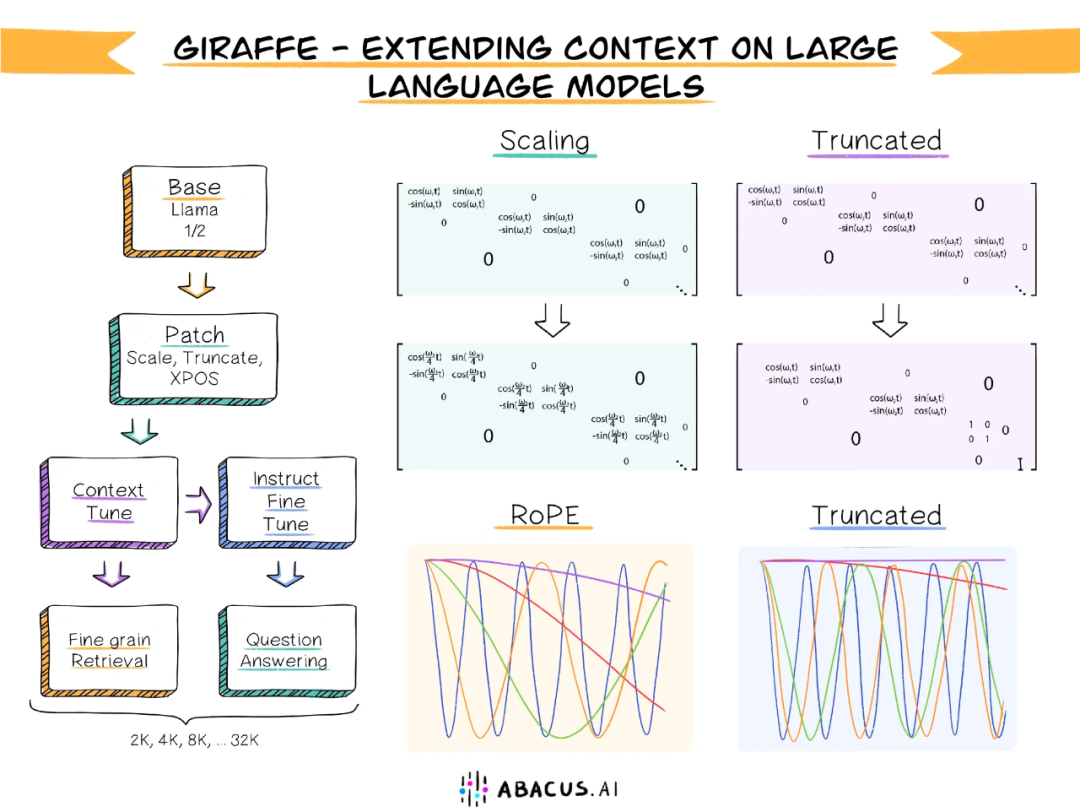
为了验证这种截断策略的有效性,本研究发布了三个新的13B参数长上下文模型——长颈鹿,其中包括两个基于LLaMA-13B训练的模型:上下文长度为4k和16k分别是;基于LLaMA2-13B训练的模型,上下文长度为32k,也是第一个基于LLMA2的32k上下文窗口开源LLM。

算盘公司首席执行官杜宾·雷迪。AI,在推特上介绍的。
32k上下文窗口是什么概念?大概是24000字,也就是说开源模型长颈鹿可以处理一篇20000字的长文。
来源:https://twitter.com/akshay帕查尔/status/1694326174158143619
方法简介
随着上下文长度的延长,LLM架构中的注意机制会成倍增加内存使用量和计算量,因此长度外推方法非常重要。
本研究整理了一些有效的外推上下文长度的方法,并对它们进行了综合测试,以确定哪些方法是最有效的,包括线性缩放、xPos、随机位置编码等。而且研究团队还提出了几种新的方法,其中一种叫做截断法,在测试中非常有效。
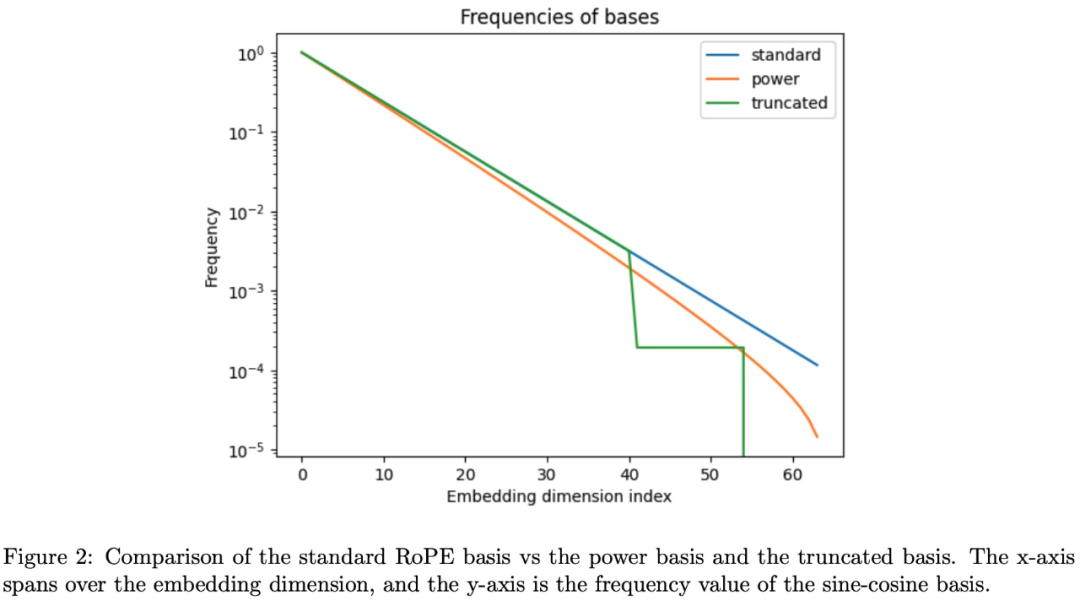
首先,评价LLM性能的难点之一是选择正确的评价方法。一个常用的指标是下一个令牌的混淆度,可以衡量模型根据上下文预测下一个令牌的能力。然而,研究团队认为,通常只需要基于整个可用上下文中的一小部分生成合理连贯的文本分布,在这个指标上就可以得到很好的结果,因此不适合长上下文。
为了分析模型在长上下文中的性能,本研究以模型召回的准确率作为衡量标准,发布了三个数据集用于评估模型在长上下文中的性能,分别是LongChat-Lines、FreeFormQA和AlteredNumericQA。其中,LongChat-Lines用于键值检索任务;FreeFormQA和AlteredNumericQA是基于自然问题数据集的问答数据集。这三个数据集可以评估LLM在键值检索任务和问题解决任务中的能力。模型关注的上下文越长,准确度就越高。
实验和结果
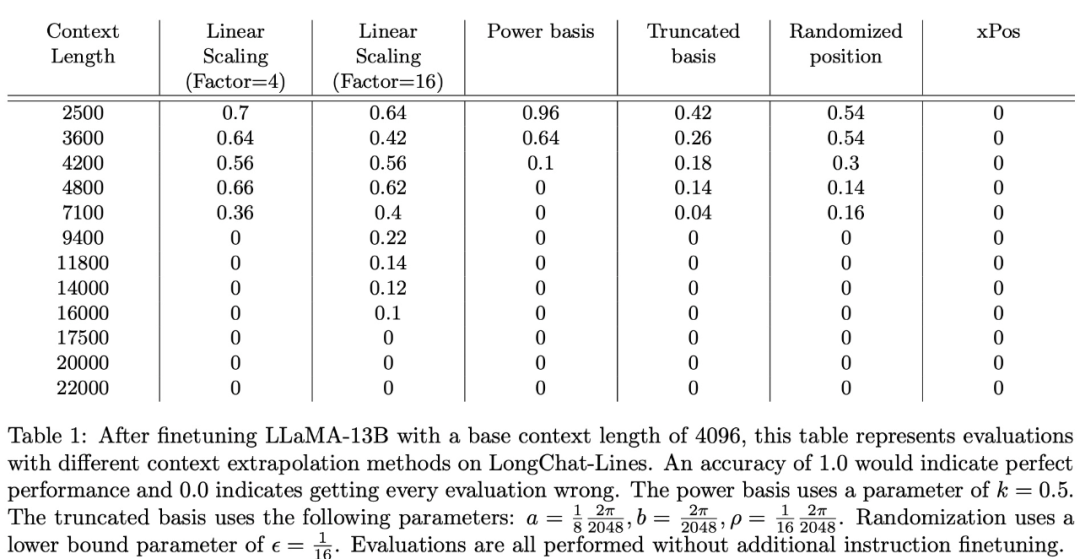
研究小组使用上述三个新数据集评估了几种上下文长度外推方法。在长聊天线上的实验结果显示在下表1中:
在FreeFormQA和AlteredNumericQA数据集上的评估结果如下面的表2和表3所示:
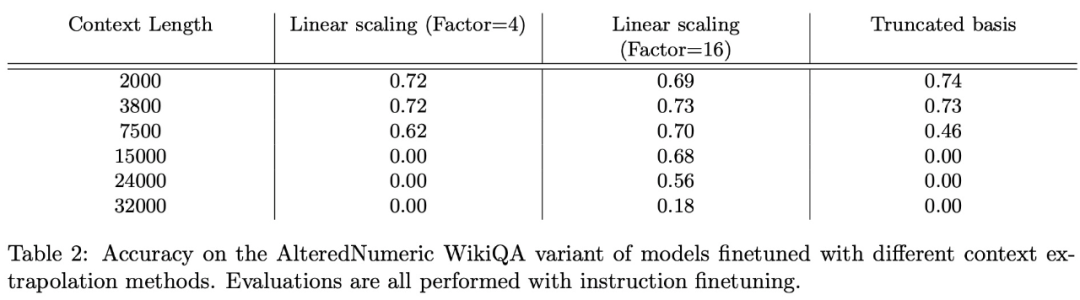
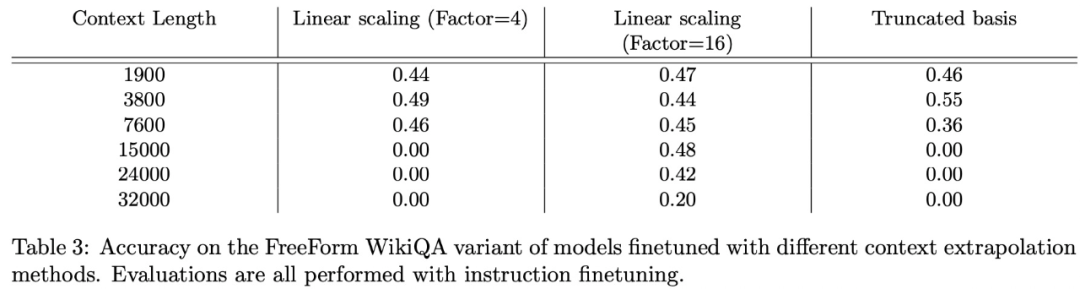
总的来说,线性缩放效果最好,截断显示了一些潜力,xPos方法在微调上无法自适应。
感兴趣的读者可以阅读论文原文,详细了解研究内容。
剧终
授权请联系本微信官方账号。
投稿或寻求报道:content@jiqizhixin.com。

 微信扫码
微信扫码
 QQ扫码
QQ扫码
您的IP:10.9.252.107,2026-06-26 09:57:10,Processed in 0.26647 second(s).
