
钱问第二波开源!8月25日,阿里云推出大规模视觉语言模型Qwen-VL,一步到位直接开源。Qwen-VL是基于70亿参数模型Qwen-7B开发的,支持图形输入,具有理解多模态信息的能力。在主流的多模态任务评估和多模态聊天能力评估中,Qwen-VL取得了远超同量表一般模型的表现。
Qwen-VL是一个视觉语言(VL)模型,支持多种语言,如中文和英文。与之前的VL模型相比,Qwen-VL不仅具备图形识别、描述、问答、对话等基本能力,还具备视觉定位、图像中文本理解等能力。
多模态是通用人工智能的重要技术演进方向之一。业内普遍认为,从只支持文字输入的单一感官语言模型,到“五官全开”支持文字、图像、音频等信息输入的多模态模型,大模型的智能有很大可能会发生跳跃。多模态可以提高大模型对世界的理解,充分拓展大模型的使用场景。
视觉是人类的第一感官能力,也是研究人员首先要赋予大型模型的多模态能力。继M6和OFA系列多模态模型推出后,阿里云依桐钱文团队基于Qwen-7B开放了大视觉语言模型(LVLM) QWEN-VL。Qwen-VL及其视觉人工智能助手Qwen-VL-Chat已在ModelScope Magic社区推出,该社区是开源、免费和商业可用的。
用户可以直接从魔骑社区下载模型,或者通过阿里云纪灵平台访问和调用Qwen-VL和Qwen-VL-聊天。阿里云为用户提供包括模型训练、推理、部署、微调在内的全方位服务。
Qwen-VL可用于知识问答、图片标题生成、图片问答、文档问答、细粒度视觉定位等场景。
比如一个不懂中文的外国游客去医院看病,不知道怎么去相应科室。他拿着一张楼层地图,问Qwen-VL“哪一层是骨科”和“哪一层是耳鼻喉科”。Qwen-VL会根据图片信息进行文字回复,这是图像问答的能力;再比如,输入一张上海外滩的照片,让Qwen-VL找到东方明珠。Qwen-VL可以用探测盒准确圈出对应的建筑,这就是视觉定位能力。
Qwen-VL是业界第一个支持中文开放域名定位的通用模型。开域的视觉定位能力决定了大模型“视觉”的准确性,也就是你能否在图片中准确找到你要找的东西,这对于VL模型在机器人控制等真实应用场景的落地非常重要。


Qwen-VL以Qwen-7B为基础语言模型,在模型架构中引入视觉编码器,使模型支持视觉信号的输入,并通过设计训练流程,使模型具有对视觉信号的细粒度感知和理解能力。Qwen-VL支持448的图像输入分辨率。以前,开源的LVLM模型通常只支持224的分辨率。在Qwen-VL的基础上,依桐钱文团队使用对齐机制创建了基于LLM的可视化AI助手Qwen-VL-Chat,允许开发者快速构建具有多模态能力的对话应用。
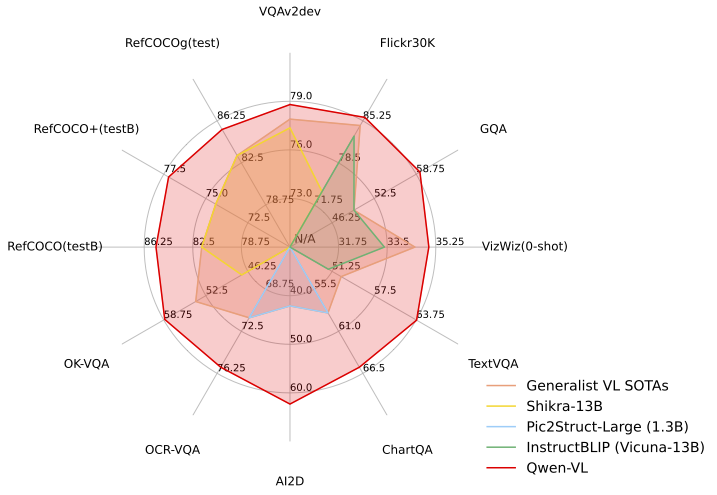
在四种多模态任务(零镜头字幕/vqa/docvqa/grounding)的标准英文评测中,Qwen-VL取得了同规模开源LVLM的最好成绩。为了测试模型的多模态对话能力,依桐钱文团队基于GPT-4评分机制构建了一套测试集“试金石”,并将Qwen-VL-Chat与其他模型进行了对比。Qwen-VL-Chat在中英文对齐评测中取得了最好的成绩。
8月初,阿里云开源依桐拥有70亿参数的通用模型Qwen-7B和对话模型Qwen-7B-Chat,成为国内首家加入大模型开源行列的大型科技企业。依桐·钱文的开源模式一经推出就受到了广泛关注。上周冲到HuggingFace潮流榜的时候,不到一个月就在GitHub收获了3400多颗星,模型累计下载量已经超过40万。
开放源地址:
ModelScope魔法社区:
https://modelscope.cn/models/qwen/Qwen-VL/summary·奎恩-VL
qwen-https://modelscope.cn/models/qwen/Qwen-VL-Chat/summary VL聊天
模特体验:https://model scope . cn/studios/qwen/qwen-VL-聊天-演示/总结。
拥抱脸:
https://huggingface.co/Qwen/Qwen-VL·奎恩-VL
qwen-Chat https://huggingface.co/Qwen/Qwen-VL-Chat VL
GitHub:
https://github.com/QwenLM/Qwen-VL
技术论文地址:
https://arxiv.org/abs/2308.12966
雷锋网(微信官方账号:雷锋网)
雷锋。com版权所有的文章未经授权禁止转载。详见转载说明。

 微信扫码
微信扫码
 QQ扫码
QQ扫码
您的IP:10.9.252.107,2026-06-26 07:26:35,Processed in 0.33971 second(s).
