
人类的视觉神经系统能够高效地感知和理解现实世界中复杂的视觉刺激,这种突出的能力是目前的人工智能系统无法比拟的。通过神经编码和解码模型来研究不同脑区的功能,可以让我们更深入地了解人类的视觉感知系统。
视觉神经编码是指将外部视觉刺激拟合为神经活动信号的过程。视觉神经解码是寻找从神经信号到相应视觉刺激的映射,是一项有意义、有挑战性的任务,根据解码的难度和目标可分为刺激分类、刺激检索和刺激重建。其中,刺激重建旨在将人脑的神经活动转化为人类能够理解的图像或视频,从而破译思维和感知。其方法是从给定的fMRI(功能磁共振成像)信号中直接生成图像,并要求其形状、位置、朝向等细节与相应的刺激图像对齐。
以往的一些研究在对手写数字、字母、人脸等简单视觉刺激的解码和重建方面取得了一定的进展,但重建结果在位置、朝向等结构信息上不可控,缺乏清晰的语义信息,难以区分。

近期,中科院自动化所的脑信息解码工作借助多模态预训练模型(如CLIP)和生成能力更强的AI模型(如Stable Diffusion),获得了语义清晰、更接近原图的重建图像。
具体来说,他们收集了“大脑-图形-文本”三模态数据集,结合了大脑、视觉和语言的知识,通过多模态变分自编码(VAE)学习,首次实现了零样本从人脑活动记录中解码出新的视觉类别。相关论文已发表在人工智能领域顶级期刊IEEE TPAMI上。
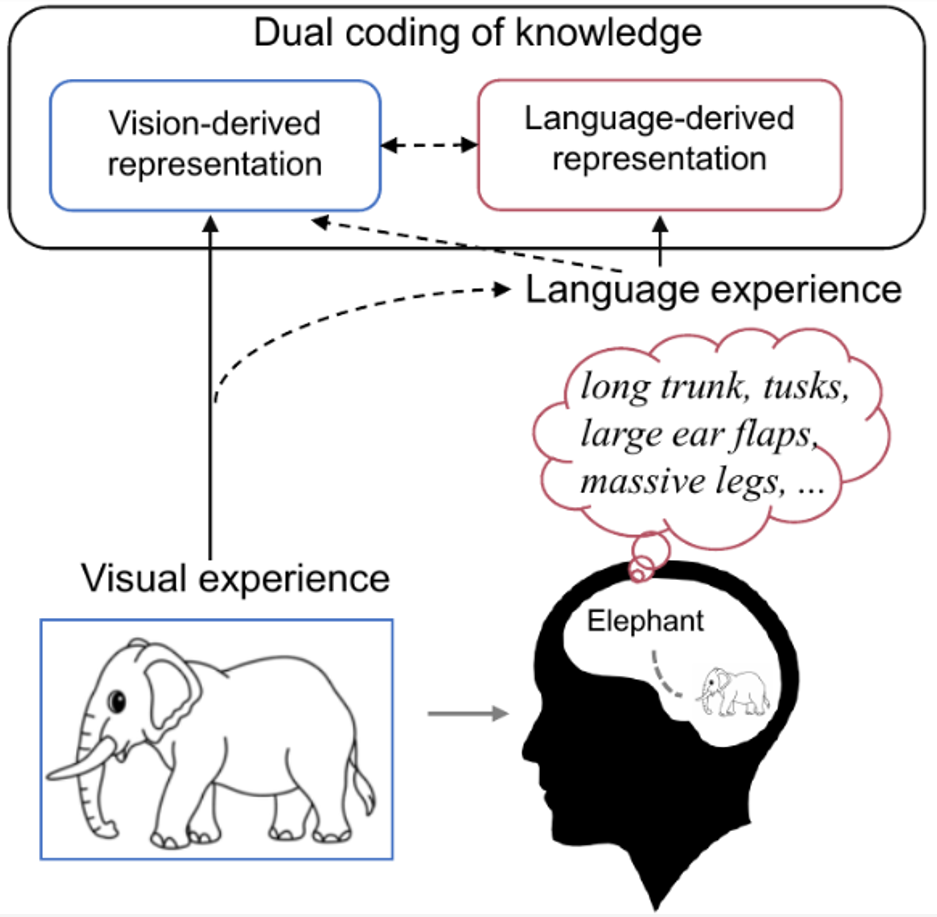
研究表明,人类对视觉刺激的感知和识别受到视觉特征和人们先前经验的影响。当我们看到一个熟悉的物体时,我们的大脑会自然而然地检索到与该物体相关的知识。比如我们看到大象的图片,自然会检索到大象的相关知识(比如长鼻子、长牙齿、大耳朵等。)在我们心目中。这时,大象的概念会在大脑中以视觉和语言的形式进行编码(双重编码),其中语言作为一种有效的先前经验,有助于塑造视觉产生的表征。因此,作者认为,为了更好地解码记录的脑信号,不仅要使用实际的视觉语义特征,还应该包含与视觉目标对象相关的更丰富的语言语义特征的组合进行解码。
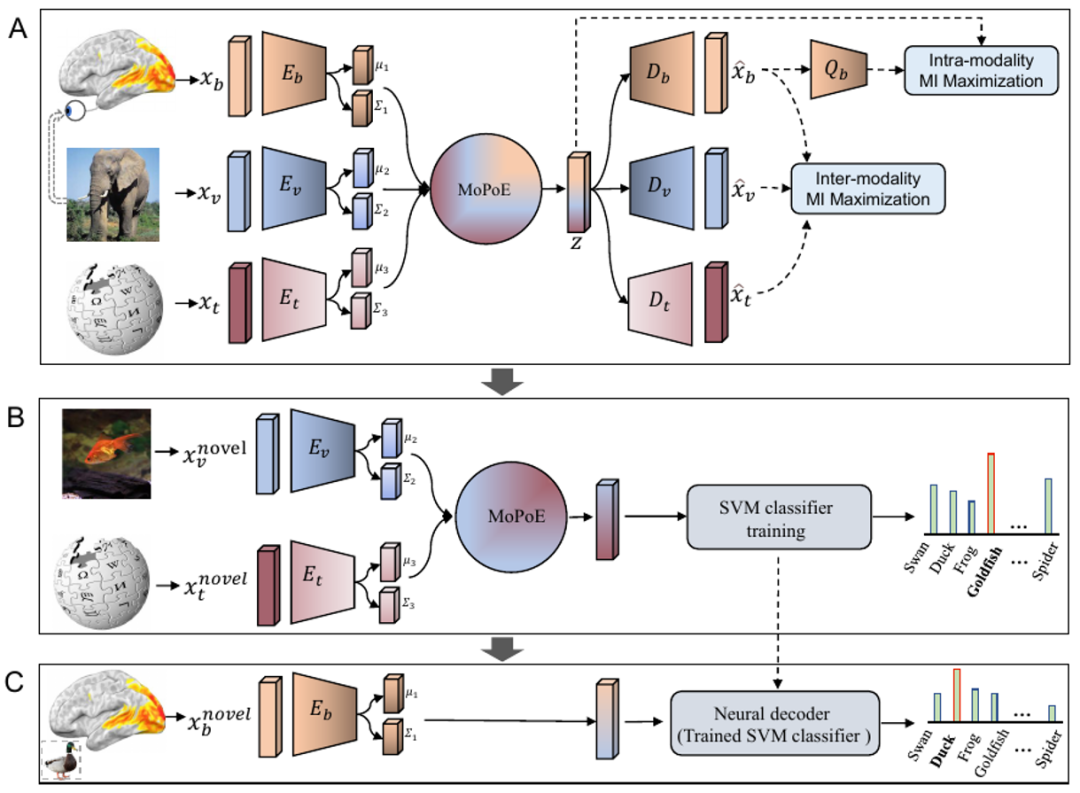
BraVL是中科院自动化所研究人员提出的“脑-图-文”三模联合学习框架。此外,他们还借助稳定扩散和CLIP提出了一种新的基于扩散模型的两阶段图像重建模型MindDiffuser,相关论文已被国际多媒体会议ACMM 2023接受。

这些结果显示了一些有趣的结论和认知见解:
有可能以高精度从人脑活动中解码出新的视觉类别。
使用视觉和语言特征的组合的解码模型比仅使用其中之一的模型执行得更好;
视知觉可能伴随着语言影响来表达视觉刺激的语义;
这项研究取得了目前最好的图像重建效果。
这些研究为理解大脑中的语义信息处理机制、开发恢复视觉功能的方法以及辅助设计脑-机接口系统提供了潜在的应用价值。
为了更好地了解这些研究成果,机器之心将于北京时间8月29日邀请两项研究的第一作者、中科院自动化所副研究员杜常德在机器之心移动组微信视频号进行技术分享。
分享主题:AI读脑:生成模型驱动的大脑信息解码与视觉重建
游客简介
杜长德,中国科学院自动化研究所副研究员,从事脑认知和人工智能研究,发表论文40余篇,包括《iScience》、《TPAMI》、《AAAI》、《KDD》、《Cell》。2019年获得IEEE ICME最佳论文亚军,2021年获得AI中文新星100强。承担了多项科技部、基金委、中科院的科研任务,研究成果在《麻省理工科技评论》头条报道。
个人主页:https://changdedu.github.io/
直播间:关注机心移动组视频号,立即预约直播。
交流群:本次直播有问答环节。欢迎加入本直播交流群讨论交流。
参考链接:
TPAMI文件地址:https://ieeexplore.ieee.org/document/10089190
TPAMI代码地址:https://github.com/ChangdeDu/BraVL
“脑-图-文”三模态数据地址:https://figshare.com/articles/dataset/BraVL/17024591
思维扩散报地址:https://arxiv.org/pdf/2308.04249.pdf
思维扩散器代码地址:https://github.com/ReedOnePeck/MindDiffuser

 微信扫码
微信扫码
 QQ扫码
QQ扫码
您的IP:10.3.203.204,2026-06-23 14:28:36,Processed in 0.05574 second(s).
