
今年4月份诞生的多模态大型语言模型MiniGPT-4,不仅可以看图聊天,还可以用手绘草图搭建网站,可以说功能强大。在预训练后的微调阶段,模型使用了3000多个数据。确实很少,但上海交大清远研究院和里海大学的一个联合研究小组认为可以更少,因为这些数据大多质量较低。他们设计了一个数据选择器,从中选取了200个数据,然后训练得到了InstructionGPT-4模型,比MiniGPT-4的性能更好,有更多的微调数据!这到底是怎么回事?
GPT-4在生成详细和准确的图像描述方面表现出了巨大和非凡的能力,这标志着语言和视觉处理新时代的到来。
因此,类似GPT-4的多模态大规模语言模型(MLLM)最近异军突起,成为一个新的研究热点。其研究核心是利用强大的LLM作为认知框架,执行多模态任务。MLLM出乎意料的优异性能不仅超越了传统方法,也使其成为实现通用人工智能的潜在途径之一。
为了创建有用的MLLM,需要使用大规模成对的图像-文本数据和视觉语言微调数据来训练冻结的LLM(如LLMA和骆马)和视觉表示(如CLIP和BLIP-2)之间的连接器(如MiniGPT-4、LLaVA和LLaMA-adapter)。
MLLM的训练通常分为两个阶段:预训练阶段和微调阶段。预训练的目的是让MLLM获得大量的知识,而微调是教会模型更好地理解人类的意图并产生准确的响应。
为了增强MLLM理解视觉语言和遵循指令的能力,最近出现了一种称为指令调谐的强大的微调技术。这项技术有助于使模型与人类的偏好保持一致,从而使模型能够在各种指令下产生预期的结果。在指令微调技术的发展中,一个建设性的方向是在微调阶段引入图像标注、视觉问答(VQA)和视觉推理数据集。InstructBLIP和Otter使用了一系列视觉语言数据集来微调视觉指令,他们也获得了潜在的结果。
然而,据观察,常用的多模态指令调优数据集包含大量低质量的示例,即响应不正确或不相关。这样的数据具有误导性,会对模型的性能产生负面影响。
这个问题促使研究人员探索一种可能性:我们能否使用少量高质量的数据来实现稳健的性能?
最近的一些研究取得了令人鼓舞的结果,表明这个方向有潜力。例如,周等人提出了LIMA,这是一种使用人类专家精心选择的高质量数据进行微调的语言模型。研究表明,即使使用有限数量的高质量数据来遵循指令,大规模语言模型也能获得令人满意的结果。因此,研究人员得出结论,少即是多。然而,对于如何选择合适的高质量数据集来微调多模态语言模型,却没有明确的指导方针。
来自上海交通大学清远研究院和里海大学的研究团队填补了这一空白,提出了一种健壮有效的数据选择器。这种数据选择器可以自动识别和过滤低质量的视觉语言数据,从而确保在模型训练中使用最相关和信息最丰富的样本。

地址:https://arxiv.org/abs/2308.12067.
研究人员表示,这项研究的重点是探索少量高质量指令调优数据对微调多模态大规模语言模型的影响。此外,本文还介绍了几个专门用于评价多模态教学数据质量的新指标。在对图像执行谱聚类之后,数据选择器计算加权分数,该加权分数结合了每个视觉语言数据的剪辑分数、GPT分数、奖励分数和答案长度。
通过对用于微调MiniGPT-4的3400个原始数据使用该选择器,研究人员发现这些数据中的大多数都存在低质量问题。使用这个数据选择器,研究人员获得了一个更小的选定数据子集——只有200个数据,只有原始数据集的6%。然后他们用了和MiniGPT-4一样的训练配置,得到了一个新型号:InstructionGPT-4。
研究人员表示,这是一个令人兴奋的发现,因为它表明,在视觉语言指令的微调中,数据的质量比数量更重要。此外,这种更加强调数据质量的变化提供了一种更有效的新范式,可以改善MLLM的微调。
研究人员进行了严格的实验,微调后的MLLM的实验评估集中在七个多样复杂的开域多模态数据集上,包括Flick-30k、ScienceQA、VSR等。他们在不同的多模态任务上比较了使用不同数据集选择方法(使用数据选择器、随机采样数据集和使用完整数据集)微调的模型的推理性能,结果显示了InstructionGPT-4的优越性。
此外,应该指出,研究人员使用的评估工具是GPT-4。具体来说,研究人员使用prompt将GPT-4变成了一个评估器,它可以使用LLaVA-Bench中的测试集来比较InstructionGPT-4和原始MiniGPT-4的响应结果。
研究发现,虽然InstructionGPT-4使用的微调数据与MiniGPT-4使用的原始指令合规数据相比只有6%,但后者在73%的情况下给出了相同或更好的响应。
本文的主要贡献包括:
通过选择200个(约6%)高质量的指令跟随数据来训练InstructionGPT-4,研究人员表明,更少的指令数据可以用于多模态大规模语言模型,以实现更好的对齐。
本文提出了一种数据选择器,它使用一个可解释的简单原则来选择高质量的多模态指令遵从数据进行微调。这种方法力求在评估和调整数据子集时实现有效性和可移植性。
实验表明,这种简单的技术可以很好地应对不同的任务。与最初的MiniGPT-4相比,仅使用6%的过滤数据进行微调的InstructionGPT-4在各种任务中取得了更好的性能。
方法
这项研究的目标是提出一个简单和便携的数据选择器,它可以从原始微调数据集中自动选择一个子集。因此,研究人员定义了一个选择原则,该原则侧重于多模态数据集的多样性和质量。下面简单介绍一下。
选择原则
为了有效地训练MLLM,选择有用的多模态教学数据是非常重要的。为了选择最佳的教学数据,研究者提出了两个关键原则:多样性和质量。对于多样性,研究人员使用的方法是对图像嵌入进行聚类,将数据分成不同的组。为了评估质量,研究人员采用了一些关键指标来有效评估多模态数据。
数据选择器
给定一个可视化语言指令数据集和一个预训练的MLLM(如MiniGPT-4和LLaVA),数据选择器的最终目标是确定一个子集进行微调,并使其改进预训练的MLLM。
为了选择这个子集并确保其多样性,研究人员首先使用一种聚类算法将原始数据集分成多个类别。
为了确保所选多模式教学数据的质量,研究人员开发了一套评估指标,如下表1所示。

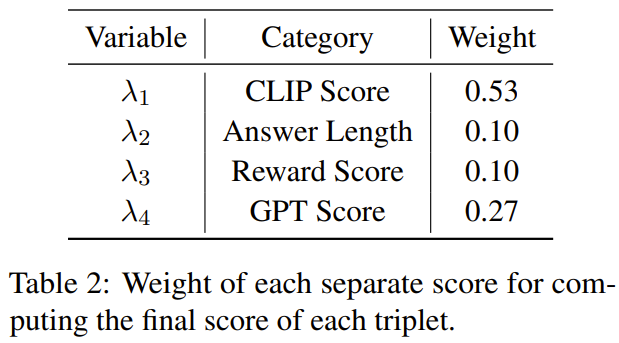
表2给出了计算最终得分时每个不同得分的权重。
算法1展示了数据选择器的整个工作流程。

实验
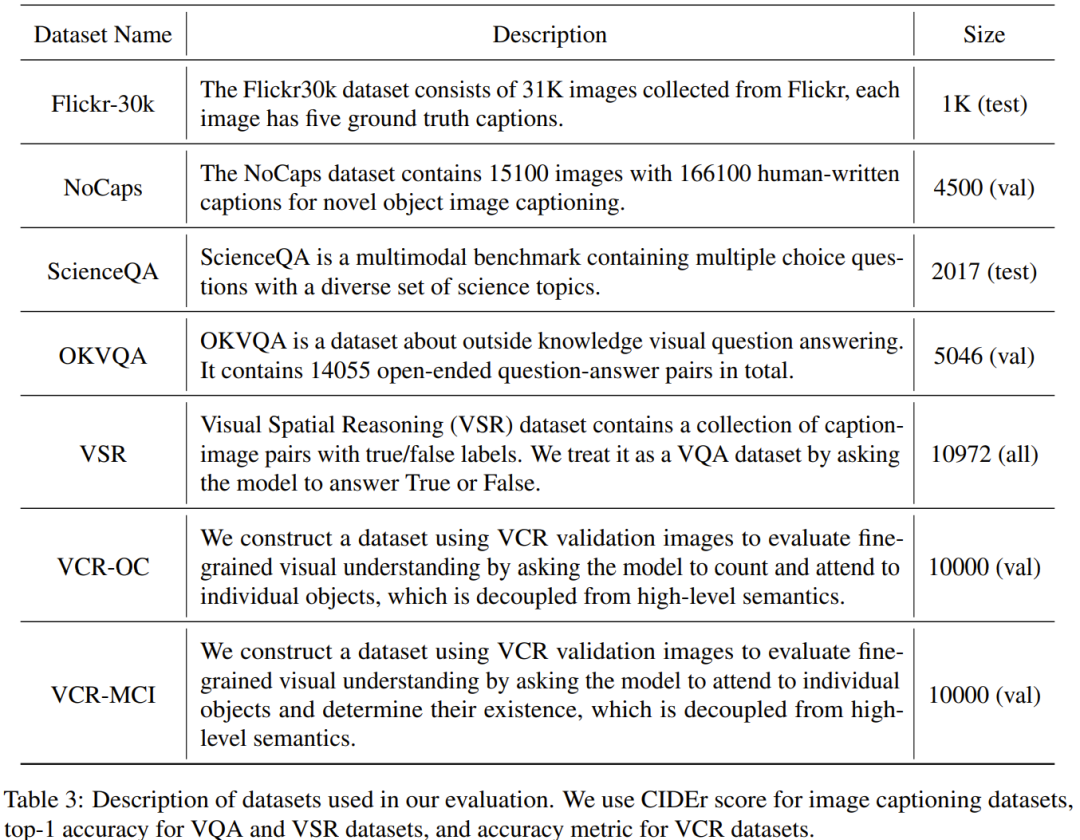
实验评估中使用的数据集如下表3所示。
基准分数
表4比较了MiniGPT-4基准模型的性能,MiniGPT-4使用随机采样数据进行微调,InstructionGPT-4使用数据选择器进行微调。
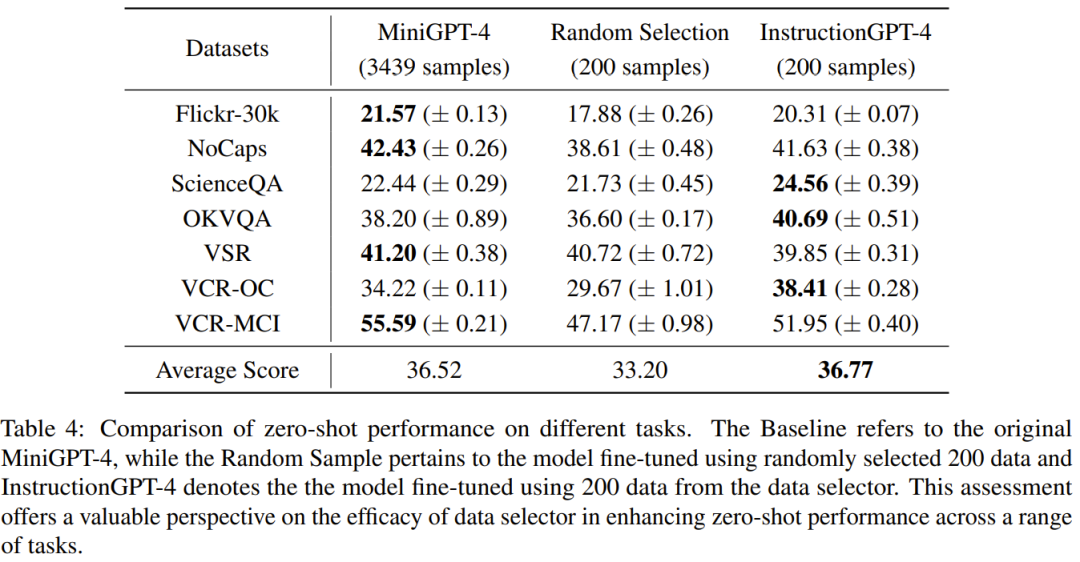
可以观察到,InstructionGPT-4的平均性能最好。具体来说,InstructionGPT-4的性能在ScienceQA中超过基准模型2.12%,在OKVQA和VCR-OC中分别超过基准模型2.49%和4.19%。
此外,InstructionGPT-4在除VSR之外的所有其他任务中均优于用随机样本训练的模型。通过在一系列任务上评估和比较这些模型,我们可以区分它们各自的能力,并确定新提出的数据选择器的效率,它可以有效地识别高质量的数据。
这种综合分析表明,明智的数据选择可以提高模型在各种任务上的零样本性能。
GPT四号评估
LLM本身就有固有的立场偏差,这一点可以在《语言模型是偷懒悄悄的吗?新研究:上下文太长,模型会跳过中间。因此,研究人员采取了措施来解决这一问题,具体来说,他们使用了两种响应序列来进行评估,即InstructionGPT-4生成的响应被放置在MiniGPT-4生成的响应之前或之后。为了制定明确的标准,他们采用了“胜负”的框架:
1) Win: InstructionGPT-4胜或两种情况都胜一次甚至一次;
2)平局:InstructionGPT-4和MiniGPT-4两次平局或者赢一次输一次;
3)输:InstructionGPT-4输两次或平一次。
图1显示了这种评估方法的结果。
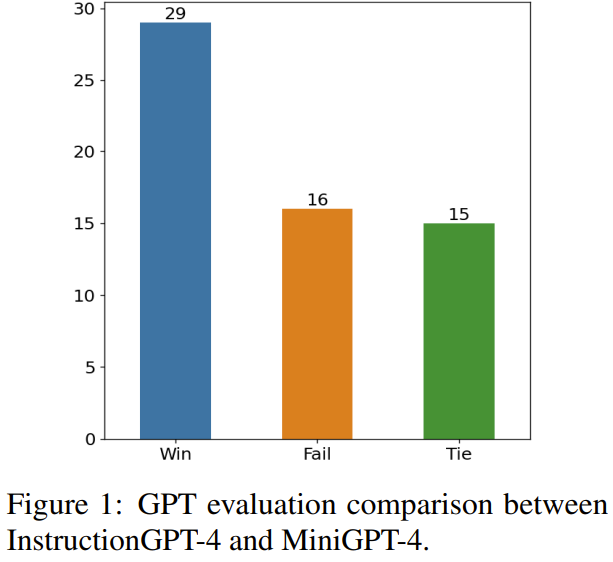
60期,InstructionGPT-4赢了29场,输了16场,剩下15场打成平手。这足以证明InstructionGPT-4在响应质量上明显优于MiniGPT-4。
消融研究
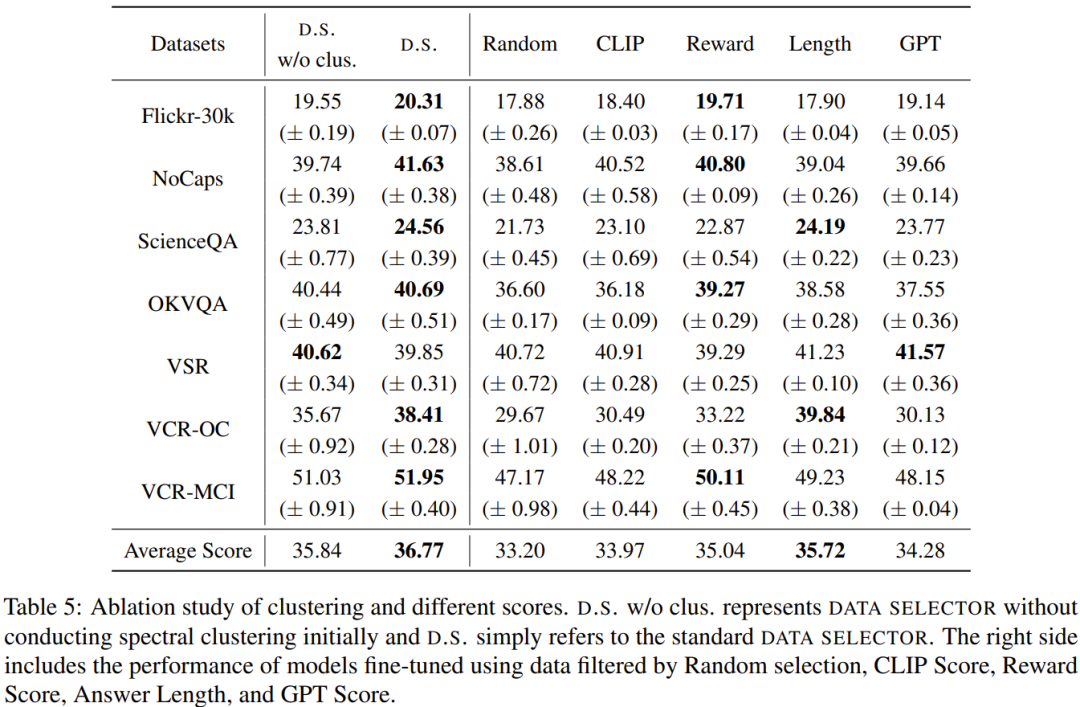
表5给出了消融实验的分析结果,从中可以看出聚类算法和各种评估分数的重要性。
证明
为了深入了解InstructionGPT-4理解视觉输入并产生合理反应的能力,研究人员还对InstructionGPT-4和MiniGPT-4的图像理解和对话能力进行了对比评估。分析基于一个显眼的例子,这个例子涉及到对形象的描述和进一步的理解。结果如表6所示。

InstructionGPT-4更擅长提供全面的图像描述和识别图像中感兴趣的方面。与MiniGPT-4相比,InstructionGPT-4更能够识别图像中存在的文本。在这里,InstructionGPT-4可以正确地指出图像中有一个短语:星期一,只是星期一。
更多详情见原论文。
剧终
授权请联系本微信官方账号。
投稿或寻求报道:content@jiqizhixin.com。

 微信扫码
微信扫码
 QQ扫码
QQ扫码
您的IP:10.3.203.204,2026-06-23 14:27:46,Processed in 0.25028 second(s).
