
资料来源:高蓉资本
在科技时代,开源不仅是一种全新的技术趋势和软件开发范式,也是无数开发者和聪明大脑不可动摇的信念。开源充分展示了一种利他精神带来的整个生态的指数级增长和大繁荣。
大模型时代,开源从一开始就成了题中应有之义。在闭源模式“北极星”的指引下,开源模式如雨后春笋,焕发出无限生机。尤其是随着LLaMA2等重磅开源模型的发布,以及commercial、Hugging Face等开源社区的兴起,开源界被认为有与闭源并驾齐驱的潜力。
回顾历史,从计算机视觉到今天的大语言模型,开源在AI的发展中起到了怎样的创新驱动作用?开源社区、开源系统建设者和开发者如何看待这片创新的土壤,期望孕育出怎样的果实?中小型或垂直创业公司如何拥抱开源AI的力量,高效开发自己的模型和应用,建立企业成长的护城河?
最近,容晖邀请了开源Infra、开源社区、开源模型和算法领域的专家,在线讨论开源AI的趋势和未来。


Meta高级副总裁比尔·贾(Bill Jia)从全球和长期的角度分享了过去10年AI生态系统各个层面的演变和开源的驱动力。
在AI模型层,开源在计算机视觉和语言翻译的发展中起着至关重要的作用。以计算机视觉为例,“CNN(卷积神经网络)一出来就是开源的,后续的一系列模型基本都是开源的,加速了多轮创新和技术迭代。”
至于今天如火如荼的大语言模式,开源大模式在不断形成生态圈的同时,也在带动闭源大模式向下一代升级。比尔·贾预测,大语言模型将有机会拥有新的模型架构,能够理解段落之间的关系,这将是一个重要的节点。另外,大模型现在对于上下文输入主要考虑空间关系,未来的模型需要考虑输入的时间相关性,这对于视频生成和逻辑生成非常重要。这些都是目前大模式的弱点,需要研究和创新。开源的大模型也为生态系统中的开发者提供了更多的机会,包括“在未来的6到9个月内,手机很有可能会运行一些相对较小的LLM。”
除了模型层,比尔·贾还系统分析了数据层、AI训练软件平台层、AI框架层、AI硬件层的开源模式。在数据层,他预计未来会有更多优质、多样、可靠的数据集开源。“这对于未来进一步提升大语言模型的能力非常重要,也有很多商业化的机会。”

抱脸是AI开源社区的“顶流”。目前,社区内有超过26万个开源模型,4.6万个开源数据库,它抱着“未来每个公司都会有自己的模型,有自己的机器学习能力”的信念。
拥抱脸亚太区首席机器学习工程师尹一峰根据他对社区的第一手观察,分享了他对开源生态趋势的展望。
“我们对开源生态有四点观察:一是百花齐放,强大的开源模型(如LLaMA2)在开源社区发布后就像寒武纪生命大爆发一样被称为‘骆马时刻’;二是马太效应。根据我们的观察,前1%的机型有99%的下载量。第三是光速的迭代,比如LLaMA和LLaMA2的间隔很短;第四,数据为王。随着开源模型变得越来越强大,它凸显了高质量数据集和数据科学团队的价值。数据决定了训练出来的模型是否有真正的商业价值。”
关于开源商业模式的讨论由来已久。抱脸选择了“开源驱动商业”的道路,推出了一系列付费服务。尹一峰拿了BloombergGPT,Stability AI,Grammarly等。作为例子,并指出结合具体的商业场景和丰富的培训资料,开源项目也具有商业化潜力。
谈及开源与闭源世界的良性促进,尹一峰形容为“开源是闭源的地板,闭源是开源的路灯”。OpenAI等闭源巨头有资源和团队优势,从0跑到1后为开源社区点亮路灯;随着开源模型的一步步增强,很多开发者可以基于基础模型快速做出优化并应用于各种场景,也在迫使闭源模型进一步迭代。他还认为,“虽然今天闭源在大机型领域领先,但未来的开源力量最终会有与闭源并驾齐驱的潜力,就像安卓和苹果生态一样。”

OpenMMLab开源算法系统是计算机视觉领域最具影响力的开源项目之一。上海人工智能实验室青年科学家陈凯介绍了从无到有构建OpenMMLab的初心和迭代历程,以及不断向外辐射,打造有价值的开源系统的思路。
早在2018年,受统一深度学习算法框架的启发,OpenMMlab应运而生,致力于打造一个计算机视觉领域的统一算法框架,“让开发者在开发算法和应用时,可以避免花费大量时间复制不同的算法,做各种参数调优。”
此后,OpenMMlab不断发展迭代,从最早提出目标检测框架,到图形分类、语义分割、视频理解等等。“基本上每年都会推出一系列开源框架和应用,到今天,已经形成了计算机视觉领域非常完整的生态。”除了统一高级基础设施,OpenMMLab还覆盖了30+计算机视觉热点、400+算法支持、4000+预训练模型和开箱即用工具。
基于开源算法体系的广泛影响力,OpenMMLab致力于进一步扩大外延,带动一批生态项目。目前,OpenMMLab开源项目超过90000个,开源生态项目超过500个,这将进一步传播AI社区,促进产学研合作。
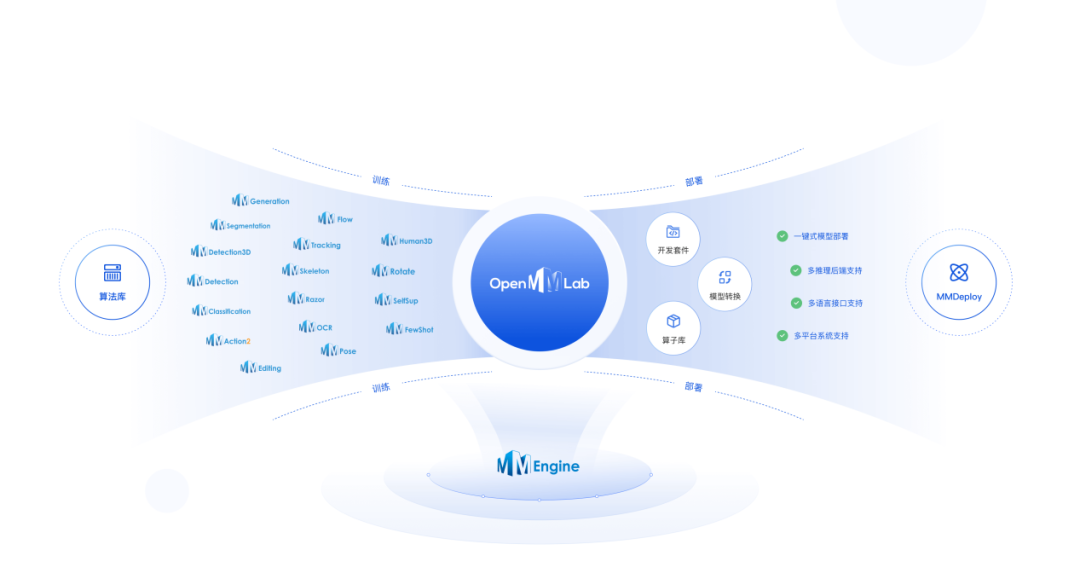
基于强大的开源生态,OpenMMLab也在计算机视觉产业上下游创造价值。上游支持芯片适配,通过算法生态推动国产软硬件生态链发展;下游将加速计算机视觉技术在企业客户端的应用,提高行业研发效率。
在大语言模型浪潮下,上海人工智能实验室也在最近的世界人工智能大会上发布了学者普宇开源模型(InternLM-7B)。除了模型本身,陈凯强调“我们希望通过开源,打造一个完整的大模型生态链。”因此,InternLM-7B围绕数据、预训练、微调、部署、评估等关键环节,构建了完整的开源体系。“最终目标是让社区更好地被利用。”

开源生态不断拓宽了AI版图的边界,为创业者和开发者提供了绝佳的创新机会。那么,创业公司应该如何拥抱这股汹涌的开源力量呢?在对话环节,高蓉资本高级副总裁王慧与多位专家探讨了大模型时代企业构建成长护城河的技巧。
秘诀一:保护核心业务,拓展版图。
面对大模型和开源带来的机遇和挑战,比尔·贾的建议是“先造城,再造护城河”。企业首先要准确认识自己在行业中的生态位置,牢牢守住自己的核心业务和底线,“看好自己的奶酪”;其次,要对大模型和开源持开放态度,思考是否有可能基于新技术拓展自己的业务,开疆拓土;最后,大模式带来的变化,就像第四次工业革命一样,最终会把蛋糕一起做大。在这个过程中,要想好哪些关键地图可以尽早切掉。
技巧二:模型选择综合考虑业务场景、合规性等因素。
开源模式百花齐放。企业如何选择最适合自己的模式?抱脸中国区负责人王铁震指出,仅仅依靠学术评价是远远不够的。企业需要测试自己的业务场景,使用专属数据集综合评估模型的能力是否匹配。比如文圣图的车型选择时,审美评分不是唯一标准,而是是否全面符合企业的目标受众和场景。这再次体现了企业建立自己数据集的重要性。“数据集的投资回报是非常长期的。以后不管是谁最火的模型,都可以用来训练和评估。”
此外,王铁铮还建议,企业在选择开源模型时,要注意当地的合规性和监管政策,包括模型许可是否商用、模型训练的透明度、训练数据的版权、数据是否符合价值观等。
企业的竞争最终取决于人才。王铁铮还特别建议创业公司可以利用开源社区寻找优秀人才,打造自己的竞争力。如果企业开辟垂直领域模式,可以挖掘社区中优秀的开发者和贡献者,帮助企业更有针对性地锁定和筛选人才。
技巧三:型号差距不用太担心,但不是破。
针对开源模型和闭源模型的性能差距,陈凯指出,开源模型的迭代速度非常快,企业要更加专注于自己的业务场景和流程,模型可以不断的替换和迭代。“有可能你今天觉得模型无效,一个月后出现新的开源模型,之前的问题就解决了;此外,我们还发现开源模式的规模也在不断增加,从之前常见的7B到13B、30B甚至更多。”
在这样的竞争格局下,初创企业是“快而不可破”的。“有些赛道非常滚动,企业需要以更高的效率运行一个垂直的应用和一个核心的场景,然后从现实世界中积累更多的用户反馈和数据,形成数据飞轮,把时间优势变成企业的护城河。”
技巧四:沉淀有核心竞争力的数据,长期投入。
十方融海创始人黄冠结合企业一线实践,分享如何基于核心业务应用ai大模型。
作为一家数字化职业在线教育科技公司,十方融海目前专注于如何利用ai创新引擎提升学生的学习体验和教学效率。起初,十方融海利用大模型技术帮助学生制作短视频,然后辅助文案生成。之后探索用AI批改语言创作作业;并进一步思考是否可以基于大模型高效回答学生提出的基础的、知识性的问题,提高助教的效率。
“我们快速学习、尝试、迭代,从今年4月开始,基于LLaMA做了微调,开发了OpenBuddy-LLaMA系列开源模型,理解和回答问题的能力非常出色。”在此过程中,黄冠和团队还通过模型优化和数据标注来提高回复的准确率,并探索模型的多轮对话能力。同时,通过在核心业务场景中迭代模型,公司也沉淀了具有核心竞争力的数据。
今年8月,什邡融海发布并开放了OpenBuddy-LLaMA2-70B模型,这是一个全新的基于LLaMA2基座的跨语言对话模型,在什邡融海内部业务的商业场景测试中取得了非常好的效果。
面向未来,黄冠对中文开源模式和中文语料库抱有期待,并“做好长期投资的心理准备”,“不要高估大模式的短期效果,也不要低估大模式的长期影响”。
流水不争第一,却生生不息。开源模式令人目不暇接,但对于企业来说,最终的命题仍然是是否足够开放来拥抱技术变革,是否足够坚定来守住核心场景。





 微信扫码
微信扫码
 QQ扫码
QQ扫码
您的IP:10.3.203.204,2026-06-23 08:12:08,Processed in 0.26024 second(s).
