
性能更强,效率更高,成本更低,谷歌迎来了自己AI芯片的升级。
长期以来,谷歌已经建立了行业领先的AI能力,如引领新一代人工智能发展的Transformer架构和由AI优化的基础设施。其中,谷歌云致力于提供先进的AI基础设施服务,包括GPU和TPU。
当地时间8月29日,Google Cloud举办了Google Cloud Next’23第23届年会,并推出了全新的TPU产品——云TPU V5 E,这是一个AI优化的基础设施产品组合,将成为迄今为止性价比最高、功能最全、可扩展的云TPU。目前有一个预览版本。
我们知道,TPU v5e可以与谷歌Kubernetes引擎(GKE)、用于构建模型和AI应用的开发者工具Vertex AI以及Pytorch、JAX和TensorFlow等深度学习框架集成,提供易于使用和熟悉的界面。
谷歌云还推出了基于英伟达H100 GPU的GPU超级计算机A3 VMs,以支持大规模AI模型。该产品将于9月全面上市。

谷歌首席科学家、知名学者杰夫·迪恩(Jeff Dean)的推特。
此外,在活动上,谷歌还宣布将Meta和Anthropic等公司的AI工具(如Llama 2和Claude 2)添加到其云平台中,将强大的生成式AI能力集成到云产品中。目前,包括Llama 2和Claude 2在内,谷歌云的客户可以使用100多个强大的AI模型和工具。
与TPU v4相比,TPU v5e在哪些方面进行了升级?
这次谷歌云推出的TPU v5e性能和易用性如何?让我们来看看吧。
根据官方数据,云TPU v5e为中大型训练和推理带来了高性能和高性价比。这一代TPU可以说是专门为大型语言模型和生成式AI模型打造的。与上一代TPU v4相比,每美元的训练性能提高了2倍,每美元的推理性能提高了2.5倍。而且TPU v5e的成本不到TPU v4的一半,这让更多的组织有机会训练和部署更大、更复杂的AI模型。

值得一提的是,由于技术创新,这些成本优势不需要牺牲任何性能或灵活性。谷歌云使用TPU v5e pods来平衡性能、灵活性和效率,允许多达256个芯片互联,总带宽超过400 Tb/s,INT8性能为100 petaOps。
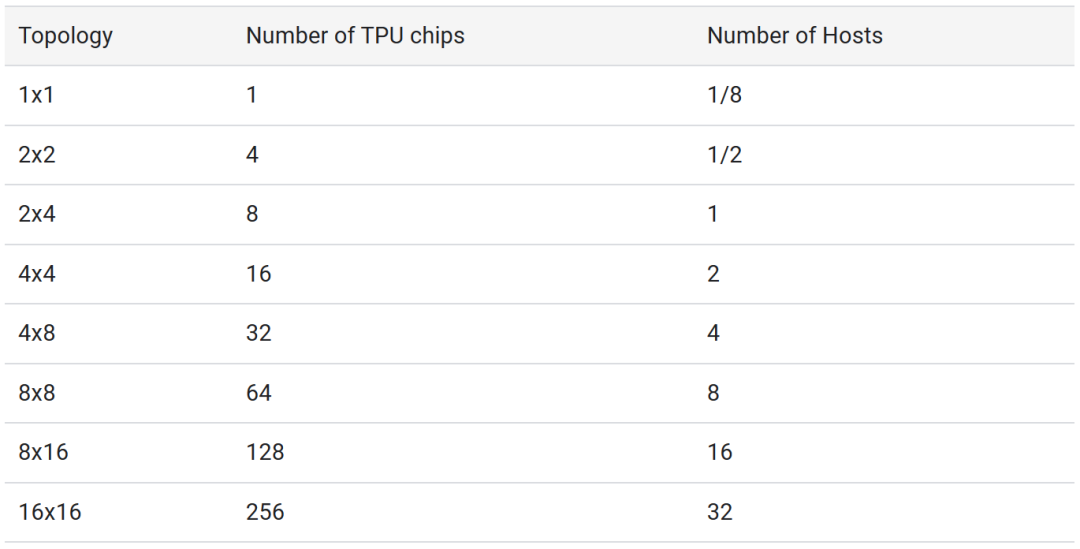
TPU v5e还具有很强的通用性,支持8种不同的虚拟机配置,单个芯片的芯片数量可以从1个到256个不等,允许客户选择合适的配置来支持不同规模的大型语言模型和生成式AI模型。
除了更强的功能和性价比,TPU v5e的可用性也达到了一个新的高度。现在客户可以通过Google Kubernetes Engine(GKE)管理TPU v5e和TPU v4上的大规模AI工作负载调度,从而提高AI开发的效率。对于喜欢简单托管服务的组织,Vertex AI现在支持使用云TPU虚拟机来训练不同的框架和库。
此外,如上所述,云TPU v5e为领先的AI框架(如JAX、PyTorch和TensorFlow)以及流行的开源工具(变形金刚和Huggingface的Accelerate、PyTorch Lightning和Ray)提供内置支持。即将发布的PyTorch/XLA 2.1版本将支持TPU v5e以及大规模模型训练的建模和数据并行等新功能。
最后,为了更容易地扩展训练工作,谷歌云在TPU v5e的预览版中引入了Multislice技术,使用户可以轻松扩展AI模型,它可以超越物理TPU吊舱的范围,最多可以容纳数万个TPU v5e或TPU v4芯片。

到目前为止,使用TPU的训练工作仅限于单个TPU芯片,TPU v4的最大切片数为3072。借助Multislice,开发人员可以在单个Pod中使用ICI(片上互连)技术,或者通过数据中心网络(DCN)上的多个Pod将工作负载扩展到数万个芯片。
这种多层切片技术为谷歌构建其最先进的PaLM模型提供了支持。现在谷歌云的客户也可以体验这项技术。
升级后的TPU v5e得到了客户的高度认可。AssemblyAI技术副总裁多梅尼克·多纳托(dome NIC Lawrence)表示,当使用TPU v5e在他们的ASR(自动语音识别)模型上运行推理时,每美元的性能总是市场上同类解决方案的4倍。这种软件和硬件的强大结合可以为他们的客户提供更具成本效益的AI解决方案。
随着谷歌云不断升级其AI基础设施,越来越多的客户将选择使用谷歌云服务。根据谷歌母公司Aplabet的数据,超过一半的生殖式AI创业公司正在使用谷歌的云计算平台。
对于谷歌来说,云TPU v5e是进一步改变产品模式和授权云客户的前奏。
参考链接:https://cloud . Google . com/blog/products/compute/announcing-cloud-TPU-v5e-and-a3-GPU-in-ga。

剧终
授权请联系本微信官方账号。
投稿或寻求报道:content@jiqizhixin.com。

 微信扫码
微信扫码
 QQ扫码
QQ扫码
您的IP:10.3.203.204,2026-06-22 02:08:37,Processed in 0.38451 second(s).
