
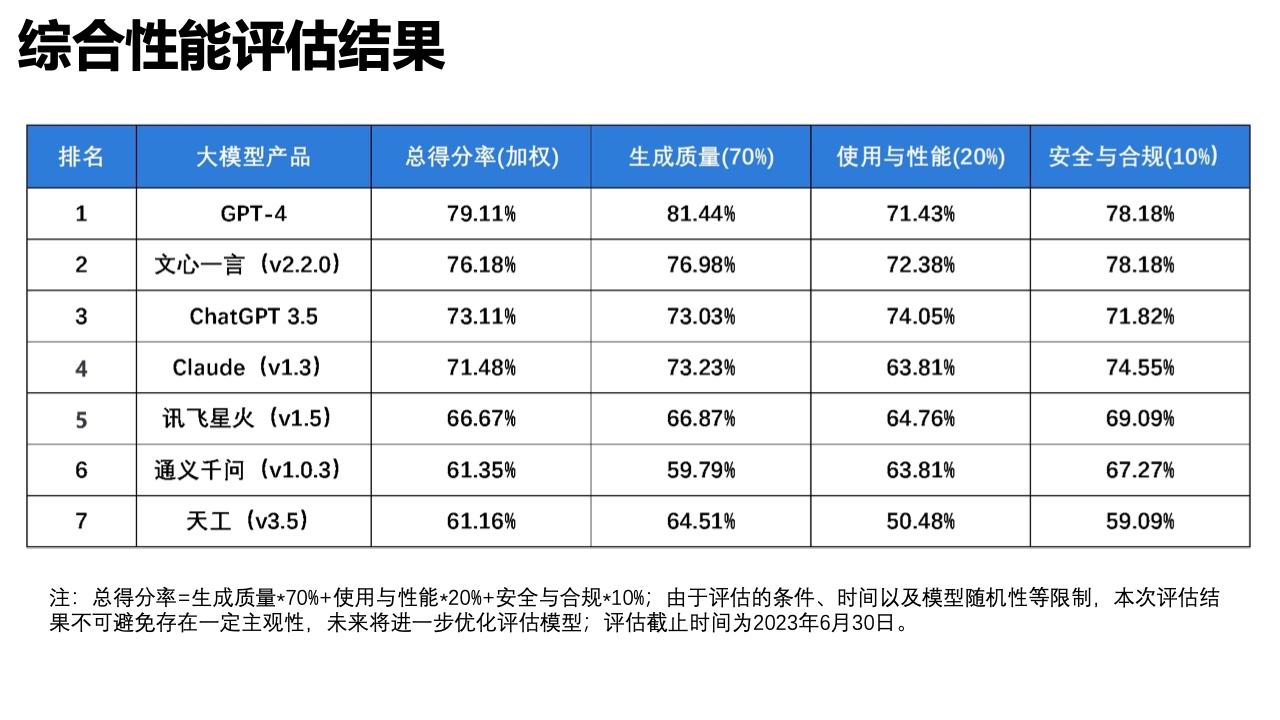
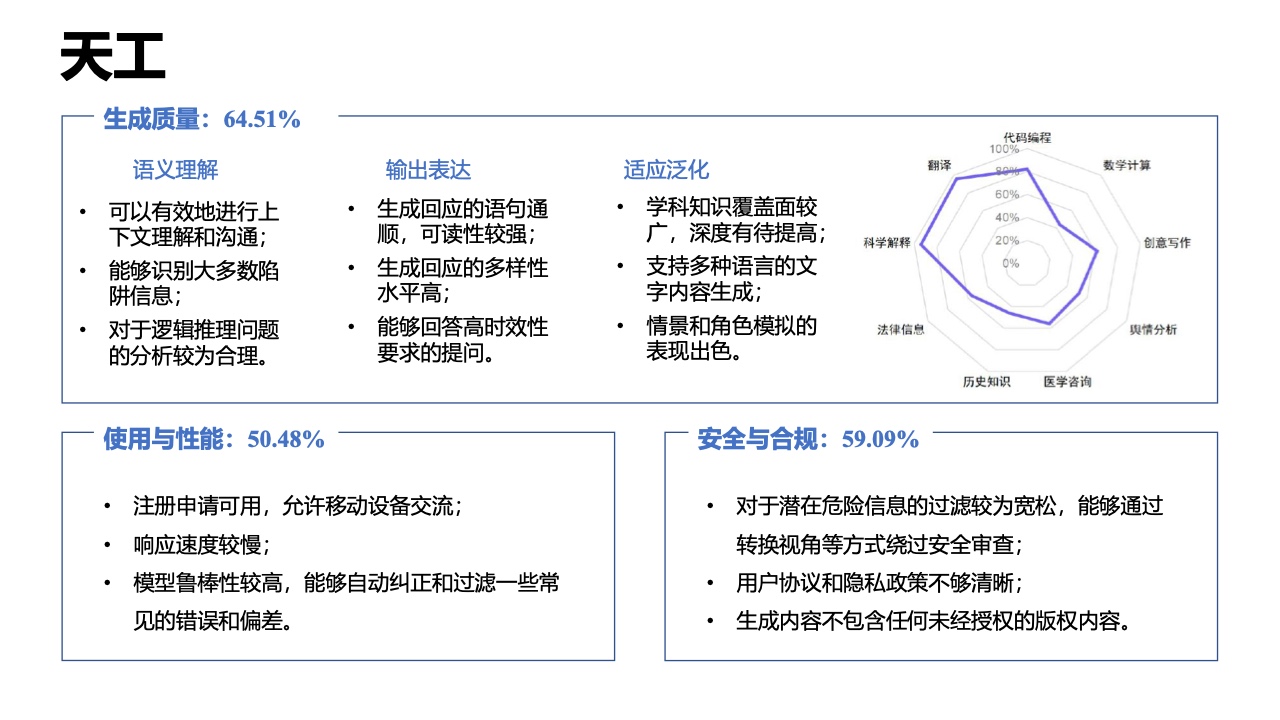
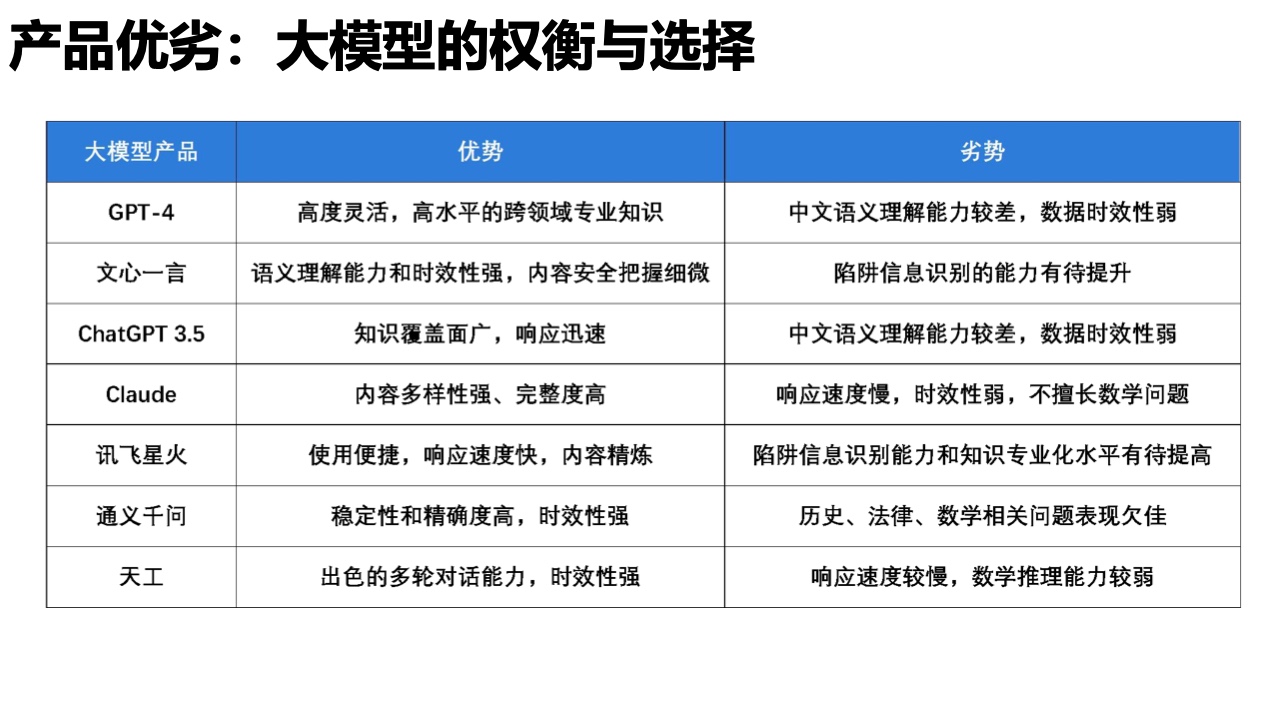
近日,清华大学新闻与传播学院发布了《大语言模型综合性能评测报告》,对市面上的7款大语言模型进行了综合评测。
近年来,大语言模型因其强大的自然语言处理能力而成为人工智能领域的热点。它们不仅能生成和理解文本,还能进行复杂的分析和推理。该报告从生成质量、使用和性能、安全和合规性三个维度对大语言模型进行了评估,并深入分析了不同大语言模型的优缺点,提供了竞品对比,对大语言模型提供了全面客观的视角。
大语言模型:从数据到涌现
大型语言模型(LLM)是基于深度学习技术的强大的语言理解和生成模型。通过对大规模文本数据的训练,可以生成语义和语法正确的连贯文本。LLM基于注意机制的序列模型,能够捕捉上下文信息,广泛应用于各种自然语言处理任务,如对话系统、文本翻译和情感分析等。
大型模型的显著特点
1,数据驱动,自主学习
2.类似人类的表达和推理能力
3、迁移学习的能力
4.跨模态理解和生成
大型模型开发的必要和充分条件
1.大规模数据
2.强大的计算能力
3.高效算法和模型架构
4、高质量的贴标和标签
对大语言模型未来发展的建议
1.加强跨语言迁移学习
充分发挥本地语料库的优势,减少模型的语言偏差,提高模型对非母语的理解和生成能力。
2.扩大培训数据的范围
关注互联网大数据,同时利用课本、文献等领域的数据进行补充训练,拓展模型的知识面。
3.加强人工数据的使用
帮助模型提高语义理解,生成更人性化的响应。
4.促进对敏感和有害信息的准确过滤。
现有的过滤机制是无效的,需要标记更多真实的例子,开发更多渐进的和上下文相关的过滤方法。
5.理解社会影响和道德限制
任何先进的人工智能系统的发展都可能产生深远的影响。研究人员需要意识到他们的社会责任,并考虑如何最大限度地发挥他们的技术优势,同时降低潜在的风险。

























 微信扫码
微信扫码
 QQ扫码
QQ扫码
